
Projects
Causal Feature Learning
Unsupervised Formation of High-level Causal Hypotheses from Low-level Data
PIs: Frederick Eberhardt (HSS Division), Ralph Adolphs (HSS, BBE Divisions)
SASE: Iman Wahle (Scholar) and Jenna Kahn (Scholar)
A key part of scientific discovery is understanding the causal relationships between variables. Researchers often ask how a change in one variable affects changes in another. In order to ask these questions, though, researchers must first decide what variables to consider in the first place. If one is interested in the relationship between brain activity and human behavior, should they look at the effects of individual neuron activity, total activity across the entire brain, or another measure altogether?
While higher-level summaries of data (i.e. total activity across the brain) are often most intuitive to work with, they can also obscure effects that are only apparent from finer-grained measurements. For this reason, these “macro-variables” must be constructed with the relation between cause and effect variables in mind. However, most research workflows today draw upon prior domain knowledge to define these macro-variables manually, without taking the relational information into consideration.
Causal Feature Learning (CFL) is an algorithm that addresses this challenge by principally aggregating fine-grained cause and effect data into coarser macro-variables that preserve the causal relations present in the original data measurements. In partnership with the Schmidt Academy, the Eberhardt and Adolphs groups set out to implement the CFL algorithm as a Python package that can be applied to data from any domain, making it possible for researchers to identify causal macro-variables in their field in an unsupervised manner.
CFL is now an open-source (academic) Python package.
For tutorials and documentation, please visit the ReadTheDocs page.

CFL identifies macro-level variables from micro-level data while taking causal relations into account. Here, equatorial pacific wind speed and sea surface temperature (SST) measurements are aggregated into macro-variables such as westerly winds and El Niño, respectively.
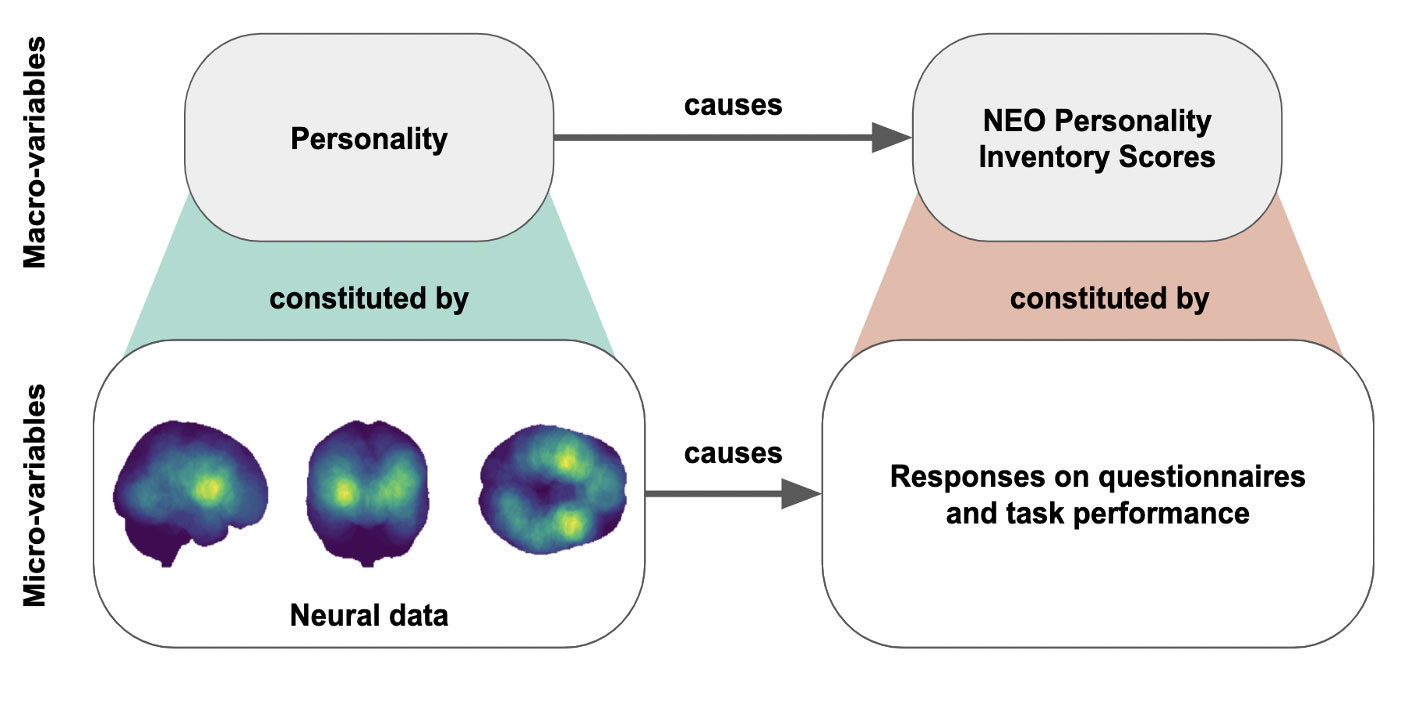
With a generalized implementation of the algorithm, CFL can be used to learn macro-variables from datasets across scientific fields. In neuroscience, for example, CFL could propose candidate causal variables like personality from neural data, which may have an effect on candidate macro-variables drawn from micro-variable questionnaire responses.